Després d’un avenç en el qual ens allunyàvem de visions apocalíptiques, i senyals de fum dissenyats per distreure als menys versats, en la nostra primera visió general d’aquest tipus de tecnologies, continuem posant context d’ús d’aquestes IA com a eines d’útil aplicació a problemes que ja havíem d’afrontar, i fins i tot altres de nous que ja podem plantejar-nos gràcies a la potència, i el diferent enfocament de resolució, que habiliten.
I és que la IA, com a concepte més que genèric, però abans que res les múltiples tecnologies i tècniques que engloben passen a convertir-se en uns elements de caràcter fonamental en el tractament actual i futur dels models de dades, des dels nivells inicials d’ingestió, fins a la seva explotació a últims nivells d’anàlisi i exposició.
Si parlem de dades, en aquests últims anys la ja desgastada frase “les dades són el nou petroli” encunyada pel matemàtic britànic Clive Humby, allà per 2006, ens porta inexorablement a la necessitat de comptar amb processos complexos per al seu tractament i refinament per obtenir la desitjada informació i el conseqüent desitjat coneixement que contenen en potència. Això ens porta a reflexions molt més vetustes, com la també repetida frase “el coneixement és poder” popularitzada per Thomas Hobbes a mitjans del segle XVII, i aproximacions més actuals que han resultat en projectes complexos que la IA està cridada a optimitzar, gràcies a unes eines amb un enfocament molt diferent del tradicional.
Una sèrie de problemes a resoldre que han convertit a les diferents facetes de la IA en una capsa d’eines d’obligada aplicació
I és que el tractament dels volums ingents (i creixents de forma exponencial) d’informació, la seva heterogeneïtat, les qüestions al voltant de la qualitat i completesa dels mateixos... Han anat posant a sobre de la taula al llarg dels últims anys, una sèrie de problemes a resoldre que han convertit a les diferents facetes de la IA en una capsa d’eines d’obligada aplicació en projectes d’aquest calibre i complexitat. Al llarg d’aquest article veurem, amb alguns àmbits com a exemple, com ens pot ajudar la IA en els projectes de tractament de dades i que ja estem aplicant en el nostre dia a dia (deixarem les visions més futuristes per a pròxims lliuraments).
Integració i neteja de dades

Aquestes tecnologies són aplicables des de les primeres fases del tractament de dades en els nostres projectes. La pròpia ingesta d’informació es pot veure beneficiada habilitant el tractament, per exemple, de dades no estructurades (que tradicionalment quedaven en zones fosques, o supeditades a donar-se suport en un subconjunt de metadades) basant-nos en processament de llenguatge natural (NPL), que ens permeti estandarditzar aquests documents origen, pdf, arxius office, obtenint-ne informació que pugui ser classificable i analitzable en següents passes dels nostres processaments de transformació i processat.
Així mateix, fa més benèvola la tediosa tasca de la neteja de dades (o data cleaning). A la selecció manual d’alternatives, o els processos pseudomanuals de reassignació i neteja de dades per substitució els pot ser donat suport per algoritmes d’imputació de dades (més o menys automatitzats) que permetin assignar valors probables o esperables sobre dades absents (o dades que es detecten obertament incorrectes. Tècniques com K-Nearest Neighbors (KNN) troba valors similars o comparables en altres registres que es troben “a prop” del registre amb la dada absent que estem processant, o altres de més complexes i amb un enfocament més iteratiu com l’algoritme MICE.
És habitual trobar dades absents, o inconsistents en els nostres orígens de dades. Conjunts de dades padronals, per exemple, on l’edat, l’adreça o l’estat civil del ciutadà no es corresponen amb l’esperat, o directament no es troben degudament informats. Aquests algoritmes d’imputació de dades absents permeten assignar valors esperables d’acord amb el comportament de ciutadans més similars en funció d’ubicació, ingressos o composició familiar, bé simplement facilitar la detecció de valors absents, o encara és més potencialment inconsistents, podent notificar els gestors responsables del tractament per a la seva revisió manual.
Classificació i segmentació de la informació
Quan processem informació, un element clau és poder classificar l’esmentada informació entorn de determinats valors o característiques. Tradicionalment aquestes segmentacions eren prefixades, per a després mitjançant pesats procediments, les dades eren processades a baix nivell per identificar-los i ubicar-los cada un d’acord amb les seves propietats i comportaments.
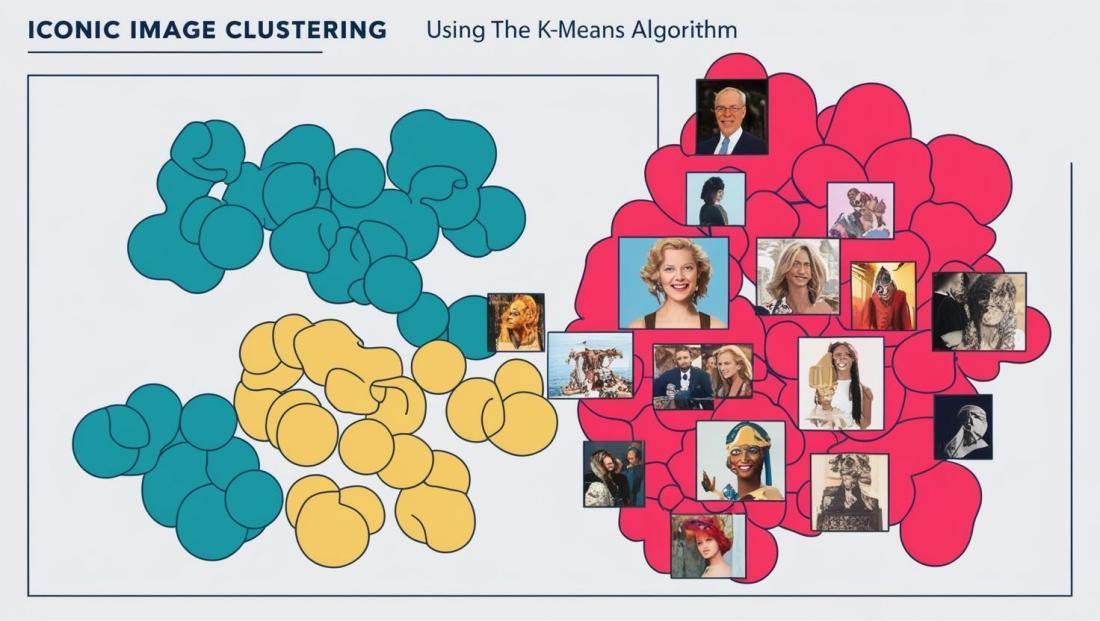
Per a la detecció d’aquests patrons, tenim tècniques clàssiques d’agrupament, més coneguts com algoritmes “clustering”, com poden ser K-Means o DBSCAN. Aquests es basen principalment a “disposar” els valors d’una determinada dimensió, partint de diverses mesures d’anàlisi, i calcular distàncies entre cada un dels esmentats valors, o directament la densitat dels mateixos. Això permet, agrupar i establir agrupacions, o segments que permeten calcular aquestes dimensions d’acord amb nous criteris de classificació associats al seu comportament.
Aquests algoritmes són àmpliament aplicables, i aplicats, quan comptem amb dades estructurades, en el cas de treballar amb aquells no estructurats, s’afegeixen a les esmentades tècniques altres per poder fer-los assumibles a un procés de segmentació. Així, per exemple, en un procés de classificació de documents legals, podem aplicar tècniques de vectorització de textos com poden ser TF-IDF o word embeddings, que ens serveixin com a base de posteriors processos de segmentació recolzats en els esmentats vectors.
Aquestes tècniques també poden aplicar-se, ja no únicament per classificar, sinó també per a detecció de patrons anòmals o que no es corresponen a comportaments esperats, o dins d’una determinada norma. Sent així aplicables per al control de frau, o de detecció de poblacions amb determinats riscos.
Així doncs, en una hipotètica estratègia de recaptació imposats, es poden aplicar aquest tipus d’algoritmes basats en dades com historials de pagament, nivells d’ingressos i fins i tot consum d’altres serveis municipals, que ens permeti generar perfils diferenciats que classifiquin el nivell de risc de morositat, o fins i tot aquelles agrupacions d’usuaris que com a grans consumidors de serveis (i pagadors, per tant) requereixen un tractament específic per la nostra part.
Securització de dades
Sempre que tractem amb dades, i és important recalcar “el sempre”, encara que hi hagi contextos que a més és d’obligat compliment, la seguretat dels mateixos en el seu tractament ha de ser una màxima que ens ha de guiar i no podem perdre de vista.
En primera instància, la IA ens pot ajudar en tots els nostres processos de xifratge i ofuscació de la informació, quan l’hem de fer passar entre els Des de la neteja i estructuració fins a la predicció i presa de decisions automatitzades, els algoritmes d’IA estan transformant la manera en què treballem amb la informació.
Descobreix com la Intel·ligència Artificial aplicada a diferents processos de transformació, en ocasions externalitzats. Basant-nos en sistemes de xifratge dinàmic, podem protegir dades sensibles tant d’accessos d’humans segons el seu nivell d’accés, com de l’accés de processos tecnològics que tinguin accés al conjunt de dades en un determinat punt (i aquests processos poden ser altres IA, que estem normalitzant en excés prestar la informació a les màquines sense les reflexions oportunes...).

Xifratge de dada estructurada, així com ofuscació i ocultació de determinada informació de documents electrònics en formats com pdf, de manera que l’accés no posi en risc la protecció de part de la informació que contenen, que al seu torn pot ser localitzada de forma automàtica, sense ser coneguda la seva ubicació per endavant, a través de tècniques d’OCR i processament de llenguatge natural (NLP).
També com a suport en la detecció d’accessos sospitosos. Analitzant per exemple les dades d’auditoria d’accés, i aplicant xarxes neuronals profundes (deep learning), podem distingir, o millor dit que el nostre sistema aprengui a distingir, entre un comportament normal, d’altres potencialment maliciosos com atacs phising, codi maliciós o denegació de servei.
Predicció de tendències i modelatge predictiu
Una de les qüestions estratègiques que en un o un altre moment acabem emprenent, com a part de la millora de la nostra estratègia basada en les dades, és intentar predir comportaments futurs, i en conseqüència les necessitats associades, de manera que puguem avançar tot el necessari per poder donar cobertura de la forma més eficient possible.

Sobre les nostres sèries de dades històriques podem aplicar tècniques com la regressió lineal, que ens permet inferir dades no conegudes, i futures en aquest espai aplicabilitat, partint d’escenaris passats i dels quals ja coneixem resultats, amb variables que, podent no ser la mateixa, tenen certa dependència o relació amb les que volem observar. A aquestes se’n sumen d’altres com els arbres de decisió, amb casuístiques més o menys prefixades i fins i tot altres de més complexes com xarxes neuronals que aplicades per a fets sobre sèries temporals, habiliten l’establiment d’escenaris predictius a través de la transmissió d’informació entre les seves capes.
Aplicant aquestes tècniques, sobre volums de dades ressenyables, combinant tendències de sol·licituds de dades anteriors, amb evolucions d’indicadors sociodemogràfics, poden establir-se models per optimitzar els recursos d’una determinada activitat. Així doncs, podem decidir la nostra estratègia general d’atenció social, partint de models predictius que ens avancen en quins llocs hem d’ampliar la cobertura dels nostres centres assistencials, quins segments de la població poden entrar (o sortir) dels grups que necessitaran aquest tipus d’atencions, o fins i tot avançar-nos de cara a fer campanyes de conscienciació o de suport preventiu a col·lectius que podem predir que necessitaran dels nostres serveis.

Vistes totes aquestes qüestions, i animats pel context, podem concloure la utilitat i beneficis de l’ús d’aquestes tecnologies en el tractament de dades, així com la seva “innegociable” utilització en afrontar aquest tipus de reptes. I és cert i innegable, però no està exempt de riscos significatius que hem de gestionar.
“En l’actualitat, res no costa més que la informació.” - A.I. Artificial Intelligence - Steven Spielberg.
“En l’actualitat, res no costa més que la informació.” - A.I. Artificial Intelligence - Steven Spielberg. Malgrat totes les tècniques i avenços, això no vol dir que la seva adopció no sigui un procés exempt d’alguns obstacles i cost.
La seva pròpia aplicació afegeix una nova capa que hem de tenir present que hem de protegir
I és que, en el tractament de totes aquestes dades, des de la seva ingesta pura com les seves diferents capes de processament i refinament podem incórrer en riscos de seguretat. És paradoxal quan dèiem que podíem donar-nos suport en la IA precisament per a securitzar informació, però la seva pròpia aplicació afegeix una nova capa que hem de tenir present que hem de protegir. I a diferents nivells, des de per on i a quines plataformes ens recolzem i els transmetem dades, perquè poden, pel camí, estar recollint informació per a altres finalitats dels desitjats.
També en cada fase del procés, podem estar deixant exposat un punt d’entrada a aquesta informació, i obrint la porta a què les dades puguin ser segrestades, o fins i tot manipulades comprometent la integritat dels resultats i les decisions que puguem prendre posteriorment a través d’elles. No hem d’oblidar, perquè simples (i de vegades gairebé-màgics) que puguin semblar aquests processos, requereixen la nostra atenció de cara a mantenir-los degudament protegits.
En la seva aplicació podem incórrer en nous biaixos algorítmics
Riscos no únicament a nivell de seguretat, la pròpia aplicació dels mateixos pot estar aportant també soroll, similar ( i en ocasions pitjor) al que pretenem eliminar. I és que en la seva aplicació podem incórrer en nous biaixos algorítmics, provocant que determinats elements deixin de ser elegibles, que determinats ciutadans mai siguin objecte d’una subvenció, o que no detectem mai una necessitat que queda fora del procés d’aprenentatge que hàgim marcat originalment. Si projectem la seva aplicació com “caixes negres” a què no reclamem prou transparència en els seus càlculs, podem estar posant un vel sobre les conclusions, que ocultin darrere de si manipulacions indegudes de la informació, discriminacions injustificades...
I a més i com no pot ser de cap altra manera, hem de fer servir aquests processos recolzats en IA, com amb qualsevol altra tecnologia, el compliment dels marcs normatius aplicables en funció de l’índole de les dades que estiguem tractant. A cap no se’ns escapa que el tractament d’informació sensible, sanitària, de situació econòmica de tots com a ciutadans, familiar etc. han de seguir subjectes a la preservació dels drets i les lleis que els protegeixen, i en la seva aplicació hem de treballar per la seva preservació. Això a més inclou tant els incipients marcs legislatius que s’estan generant sobre això, com les normes ja existents, i que apliquen a nivell general a qualsevol projecte tecnològic que treballi amb dades.
Aplicar la tecnologia de forma equilibrada
En qualsevol cas, aquests riscos, convertits en tasques a resoldre des d’un enfocament de resolució a través d’estratègies proactives, no deixen de ser part de l’aplicació de la IA als projectes de tractament de dades. No són, per tant, un element que ens hagi de frenar en la seva aplicació és simplement una qüestió que hem de tenir en compte en implantar la IA i aprofitar tota la potència i solucions que ens faciliten i fan molt més eficient els nostres processos de transformació de les dades originals, en informació d’altíssim valor en les fases posteriors de preses de decisió estratègica en els nostres processos. Parlem, així doncs, d’aplicar la tecnologia de forma equilibrada per garantir la transparència, la seguretat i l’equitat que garanteixi aprofitar tots els seus beneficis, que són molts, sense comprometre aspectes ètics i de confiança fonamentals.
L’aplicació de la IA, un procés d’implantació imparable i inevitable
Posats en una balança, i treballats amb aquestes premisses d’equilibri, l’aplicació de la IA en els projectes de tractament de dades és una realitat d’avui, i un procés d’implantació imparable i inevitable.
Hem vist, almenys en part perquè ens pugui posar en context, l’ús de les tecnologies associades a l’àmplia família que englobem amb el terme IA en el tractament de dades, en un primer estadi d’ingesta i modelatge dels mateixos. Tant el seu tractament, com els riscos i qüestions que hem de tenir en compte en la seva aplicació. També la necessitat inherent a l’aplicació de qualsevol tecnologia, i sí la IA no escapa a aquestes necessitats, que comptem amb la transparència i els mecanismes de control humans que garanteixin la seva qualitat i la correcció dels resultats i conclusions obtingudes.
Alguns arribat a aquest punt, estaran trobant a faltar la seva aplicació en següents fases com la generació de visualitzacions analítiques, l’automatització de decisions estratègiques partint dels models generats... I no ens n’hem oblidat òbviament, per la seva extensió, i el rèdit que ens conculca a tots al seu voltant, ens portarà al següent article d’aquesta sèrie en el qual el desenvoluparem amb el degut detall. “Ens llegim” ben aviat.


