Después de un avance en el que nos alejábamos de visiones apocalípticas, y señales de humo diseñadas para distraer a los menos versados, en nuestra primera visión general de este tipo de tecnologías, vamos a continuar poniendo contexto de uso de estas IA’s como herramientas de útil aplicación a problemas que ya teníamos que afrontar, e incluso otros nuevos que ya podemos plantearnos gracias a la potencia, y el distinto enfoque de resolución, que habilitan.
Y es que la IA, como concepto más que genérico, pero ante todo las múltiples tecnologías y técnicas que engloban pasan a convertirse en unos elementos de carácter fundamental en el tratamiento actual y futuro de los modelos de datos, desde los niveles iniciales de ingestión, hasta su explotación a últimos niveles de análisis y exposición.
Si hablamos de datos, en estos últimos años la ya desgastada frase “los datos son el nuevo petróleo” acuñada por el matemático británico Clive Humby, allá por 2006, nos lleva inexorablemente a la necesidad de contar con procesos complejos para su tratamiento y refinado para obtener la deseada información y el consecuente deseado conocimiento que contienen en potencia. Esto nos lleva a reflexiones mucho más vetustas, como la también repetida frase “el conocimiento es poder” popularizada por Thomas Hobbes a mediados del siglo XVII, y aproximaciones más actuales que han resultado en proyectos complejos que la IA está llamada a optimizar, gracias a unas herramientas con un enfoque muy diferente al tradicional.
Una serie de probemas a resolver que han convertido a las distintas facetas de la IA en una caja de herramientas de obligada aplicación
Y es que el tratamiento de los volúmenes ingentes (y crecientes de forma exponencial) de información, su heterogeneidad, las cuestiones alrededor de la calidad y completitud de los mismos… Han ido poniendo encima de la mesa a lo largo de los últimos años, una serie de problemas a resolver que han convertido a las distintas facetas de la IA en una caja de herramientas de obligada aplicación en proyectos de este calibre y complejidad. A lo largo de este artículo vamos a ver, con algunos ámbitos a modo de ejemplo, cómo nos puede ayudar la IA en los proyectos de tratamiento de datos y que ya estamos aplicando en nuestro día a día (dejaremos las visiones más futuristas para próximas entregas).
Integración y limpieza de datos

Estas tecnologías son aplicables desde las primeras fases del tratamiento de datos en nuestros proyectos. La propia ingesta de información se puede ver beneficiada habilitando el tratamiento, por ejemplo, de datos nos estructurados (que tradicionalmente quedaban en zonas oscuras, o supeditados a apoyarse en un subconjunto de metadatos) apoyándonos en procesamiento de lenguaje natural (NPL), que nos permita estandarizar estos documentos origen, pdfs, archivos office, obteniendo de ellos información que pueda ser clasificable y analizable en siguientes pases de nuestros procesos de transformación y procesado.
Así mismo, hace más benévola la tediosa tarea de la limpieza de datos (o data cleaning). La selección manual de alternativas, o los procesos pseudo-manuales de reasignación y limpieza de datos por sustitución pueden ser apoyados por algoritmos de imputación de datos (más o menos automatizados) que permitan asignar valores probables o esperables sobre datos faltantes (o datos que se detectan abiertamente incorrectos. Técnicas como K-Nearest Neighbors (KNN) encuentra valores similares o comparables en otros registros que se encuentran “cerca” del registro con el dato faltante que estamos procesando, u otras más complejas y con un enfoque más iterativo como el algoritmo MICE.
Es habitual encontrar datos faltantes, o inconsistentes en nuestros orígenes de datos. Conjuntos de datos padronales, por ejemplo, donde la edad, la dirección o el estado civil del ciudadano no se corresponden con lo esperado, o directamente no se encuentran debidamente informados. Estos algoritmos de imputación de datos faltantes permiten asignar valores esperables de acuerdo con el comportamiento de ciudadanos más similares en función de ubicación, ingresos o composición familiar, bien simplemente facilitar la detección de valores faltantes, o aún es más potencialmente inconsistentes, pudiendo notificar a los gestores responsables del tratamiento para su revisión manual.
Clasificación y segmentación de la información
Cuando procesamos información, un elemento clave es poder clasificar dicha información en torno a determinados valores o características. Tradicionalmente estas segmentaciones eran prefijadas, para después mediante pesados procedimientos, los datos eran procesados a bajo nivel para identificarlos y ubicarlos cada uno de acuerdo con sus propiedades y comportamientos.
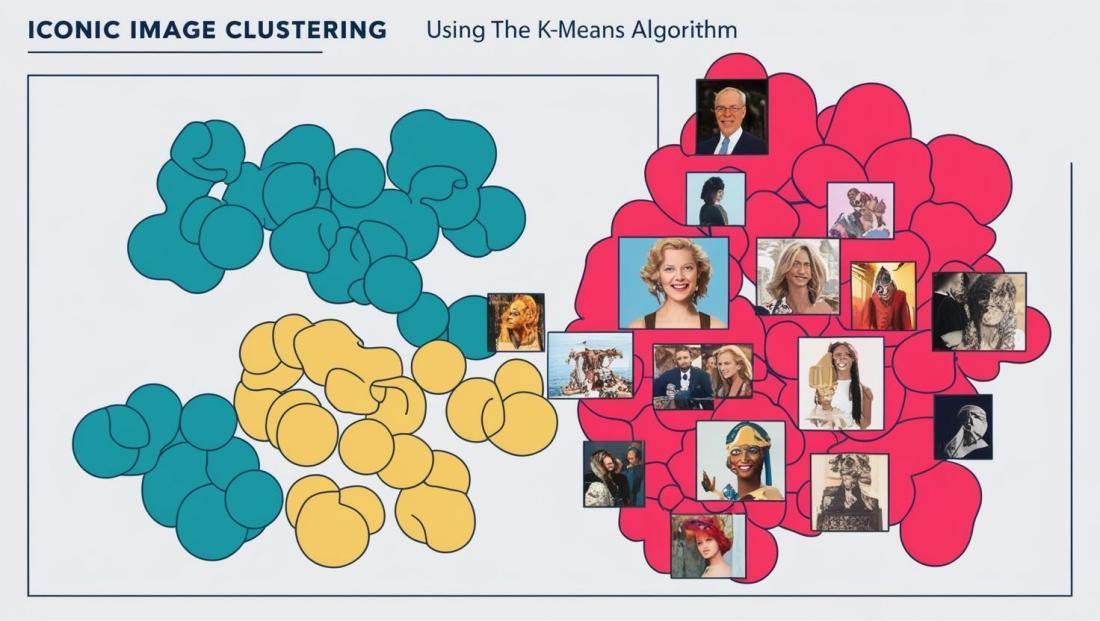
Para la detección de estos patrones, tenemos técnicas clásicas de agrupamiento, más conocidos como algoritmos “clustering”, como pueden ser K-Means o DBSCAN. Estos se basan principalmente en “disponer” los valores de una determinada dimensión, en base a varias medidas de análisis, y calcular distancias entre cada uno de dichos valores, o directamente la densidad de los mismos. Esto permite, agrupar y establecer agrupaciones, o segmentos que permiten calcular estas dimensiones de acuerdo con nuevos criterios de clasificación asociados a su comportamiento.
Estos algoritmos son ampliamente aplicables, y aplicados, cuando contamos con datos estructurados, en el caso de trabajar con aquellos no estructurados, se suman a dichas técnicas otras para poder hacerlos asumibles a un proceso de segmentación. Así, por ejemplo, en un proceso de clasificación de documentos legales, podemos aplicar técnicas de vectorización de textos como pueden ser TF-IDF o word embeddings, que nos sirvan como base de posteriores procesos de segmentación apoyados en dichos vectores.
Estas técnicas también pueden aplicarse, ya no únicamente para clasificar, sino también para detección de patrones anómalos o que no se corresponden a comportamientos esperados, o dentro de una determinada norma. Siendo así aplicables para el control de fraude, o de detección de poblaciones con determinados riesgos.
Así pues, en una hipotética estrategia de recaudación impuestos, se pueden aplicar este tipo de algoritmos basados en datos como historiales de pago, niveles de ingresos e incluso consumo de otros servicios municipales, que nos permita generar perfiles diferenciados que clasifiquen el nivel de riesgo de morosidad, o incluso aquellas agrupaciones de usuarios que como grandes consumidores de servicios (y pagadores, por ende) requieren un tratamiento específico por nuestra parte.
Securización de datos
Siempre que tratamos con datos, y es importante recalcar “el siempre”, aunque haya contextos que además es de obligado cumplimiento, la seguridad de los mismos en su tratamiento debe ser una máxima de que debe guiarnos y no podemos perder de vista.
En primera instancia, la IA nos puede ayudar en todos nuestros procesos de cifrado y ofuscación de la información, cuando la tenemos que hacer pasar entre los Desde la limpieza y estructuración hasta la predicción y toma de decisiones automatizadas, los algoritmos de IA están transformando la manera en que trabajamos con la información.
Descubre cómo la Inteligencia Artificial aplicada a distintos procesos de transformación, en ocasiones externalizados. Apoyándonos en sistemas de cifrado dinámico, podemos proteger datos sensibles tanto de accesos de humanos según su nivel de acceso, como del acceso de procesos tecnológicos que tengan acceso al conjunto de datos en un determinado punto (y estos procesos pueden ser otras IA’s, que estamos normalizando en exceso prestar la información a las máquinas sin las reflexiones oportunas…).

Cifrado de dato estructurado, así como ofuscación y ocultación de determinada información de documentos electrónicos en formatos como pdf, de manera que el acceso no ponga en riesgo la protección de parte de la información que contienen, que a su vez puede ser localizada de forma automática, sin ser conocida su ubicación de antemano, a través de técnicas de OCR y procesamiento de lenguaje natural (NLP).
También como apoyo en la detección de accesos sospechosos. Analizando por ejemplo los datos de auditoría de acceso, y aplicando redes neuronales profundas (deep learning), podemos distinguir, o mejor dicho que nuestro sistema aprenda a distinguir, entre un comportamiento normal, de otros potencialmente maliciosos como ataques phising, malware o denegación de servicio.
Predicción de tendencias y modelado predictivo
Una de las cuestiones estratégicas que en uno u otro momento acabamos acometiendo, como parte de la mejora de nuestra estrategia basada en los datos, es intentar predecir comportamientos futuros, y en consecuencia las necesidades asociadas, de manera que podamos adelantar todo lo necesario para poder dar cobertura de la forma más eficiente posible.

Sobre nuestras series de datos históricos podemos aplicar técnicas como la regresión lineal, que nos permite inferir datos no conocidos, y futuros en este espacio aplicabilidad, en base a escenarios pasados y de los que ya conocemos resultados, con variables que, pudiendo no ser la misma, tienen cierta dependencia o relación con las que queremos observar. A estas se suman otras como los árboles de decisión, con casuísticas más o menos prefijadas e incluso otras más complejas como redes neuronales que aplicadas para hechos sobre series temporales, habilitan el establecimiento de escenarios predictivos a través de la transmisión de información entre sus capas.
Aplicando estás técnicas, sobre volúmenes de datos reseñables, combinando tendencias de solicitudes de datos anteriores, con evoluciones de indicadores sociodemográficos, pueden establecerse modelos para optimizar los recursos de una determinada actividad. Así pues, podemos decidir nuestra estrategia general de atención social, en base a modelos predictivos que nos adelantan en qué lugares debemos ampliar la cobertura de nuestros centros asistenciales, qué segmentos de la población pueden entrar (o salir) de los grupos que van a necesitar este tipo de atenciones, o incluso adelantarnos de cara a hacer campañas de concienciación o de apoyo preventivo a colectivos que podemos predecir que van a necesitar de nuestros servicios.

Vistas todas estas cuestiones, y animados por el contexto, podemos concluir la utilidad y beneficios del uso de estas tecnologías en el tratamiento de datos, así como su “innegociable” utilización al afrontar este tipo de retos. Y es cierto e innegable, pero no está exento de riesgos significativos que vamos a tener que gestionar.
“En la actualidad, nada cuesta más que la información.” - A.I. Artificial Intelligence - Steven Spielberg.
“En la actualidad, nada cuesta más que la información.” - A.I. Artificial Intelligence - Steven Spielberg. Pese a todas las técnicas y avances, esto no quiere decir que su adopción no sea un proceso exento de algunos obstáculos y coste.
Su propia aplicación añade una nueva capa que tenemos que tener presente que debemos proteger
Y es que, en el tratamiento de todos estos datos, desde su ingesta pura como sus distintas capas de procesamiento y refinado podemos incurrir en riesgos de seguridad. Es paradójico cuando decíamos que podíamos apoyarnos en la IA precisamente para securizar información, pero su propia aplicación añade una nueva capa que tenemos que tener presente que debemos proteger. Y a distintos niveles, desde por dónde y en qué plataformas nos apoyamos y les trasmitimos datos, porque pueden, por el camino, estar recolectando información para otros fines de los deseados.
También en cada fase del proceso, podemos estar dejando expuesto un punto de entrada a esta información, y abriendo la puerta a que los datos puedan ser secuestrados, o incluso manipulados comprometiendo la integridad de los resultados y las decisiones que podamos tomar posteriormente a través de ellos. No debemos olvidar, porque simples (y a veces cuasi-mágicos) que puedan parecer estos procesos, requieren nuestra atención de cara a mantenerlos debidamente protegidos.
En su aplicación podemos incurrir en nuevos sesgos algorítmicos
Riesgos no únicamente a nivel de seguridad, la propia aplicación de los mismos puede estar aportando también ruido, similar ( y en ocasiones peor) al que pretendemos eliminar. Y es que en su aplicación podemos incurrir en nuevos sesgos algorítmicos, provocando que determinados elementos dejen de ser elegibles, que determinados ciudadanos nunca sean objeto de una subvención, o que no detectemos nunca una necesidad que queda fuera del proceso de aprendizaje que hayamos marcado originalmente. Si proyectamos su aplicación como “cajas negras” a las que no reclamamos la suficiente transparencia en sus cálculos, podemos estar poniendo un velo sobre las conclusiones, que oculten tras de sí manipulaciones indebidas de la información, discriminaciones injustificadas…
Y, además, y como no puede ser de otra manera, debemos emplear estos procesos apoyados en IA, como con cualquier otra tecnología, el cumplimiento de los marcos normativos aplicables en función de la índole de los datos que estemos tratando. A ninguno se nos escapa que el tratamiento de información sensible, sanitaria, de situación económica de todos como ciudadanos, familiar etc. deben seguir sujetos a la preservación de los derechos y las leyes que los protegen, y en su aplicación vamos a tener que trabajar por su preservación. Esto además incluye tanto los incipientes marcos legislativos que se están generando al respecto, como las normas ya existentes, y que aplican a nivel general a cualquier proyecto tecnológico que trabaje con datos.
Aplicar la tecnología de forma equilibrada
En cualquier caso, estos riesgos, convertidos en tareas a resolver desde un enfoque de resolución a través de estrategias proactivas, no dejan de ser parte de la aplicación de la IA a los proyectos de tratamiento de datos. No son, por tanto, un elemento que nos deba frenar en su aplicación es simplemente una cuestión que debemos tener en cuenta a la de implantar la IA y aprovechar toda la potencia y soluciones que nos facilitan y hacen mucho más eficiente nuestros procesos de transformación de los datos originales, en información de altísimo valor en las fases posteriores de tomas de decisión estratégica en nuestros procesos. Hablamos, así pues, de aplicar la tecnología de forma equilibrada para garantizar la transparencia, la seguridad y la equidad que garantice aprovechar todos sus beneficios, que son muchos, sin comprometer aspectos éticos y de confianza fundamentales.
La aplicación de la IA, un proceso de implantación imparable e inevitable
Puestos en una balanza, y trabajados con estas premisas de equilibrio, la aplicación de la IA en los proyectos de tratamientos de datos es una realidad de hoy, y un proceso de implantación imparable e inevitable.
Hemos visto, al menos en parte para que nos pueda poner en contexto, el uso de las tecnologías asociadas a la amplia familia que englobamos con el término IA en el tratamiento de datos, en un primer estadio de ingesta y modelado de los mismos. Tanto su tratamiento, como los riesgos y cuestiones que tenemos que tener en cuenta en su aplicación. También la necesidad inherente a la aplicación de cualquier tecnología, y sí la IA no escapa a estas necesidades, de que contemos con la transparencia y los mecanismos de control humanos que garanticen su calidad y la corrección de los resultados y conclusiones obtenidas.
Algunos llegado a este punto, estarán echando en falta su aplicación en siguientes fases como la generación de visualizaciones analíticas, la automatización de decisiones estratégicas en base a los modelos generados... Y no nos hemos olvidado obviamente de ellos, dada su extensión, y el interés que nos conculca a todos a su alrededor, nos llevará al siguiente artículo de esta serie en el que lo desarrollaremos con el debido detalle. “Nos leemos” en breve.

Con más de 20 años de investigación y colaboración en diferentes proyectos de analítica de datos. Cuenta con una amplia experiencia en diferentes tecnologías BI, con un foco especial en la plataforma analítica Qlik.

