Producción y gestión a largo plazo de grandes volúmenes de información
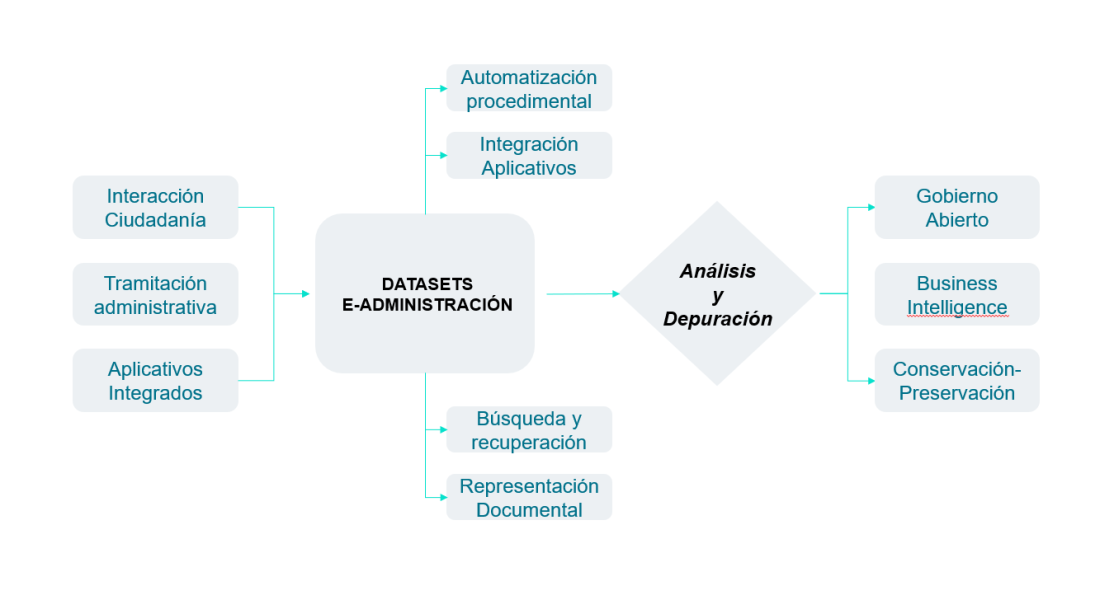
La gestión de grandes volúmenes de información (estructurada o desestructurada), en diferentes soportes y proveniente de múltiples fuentes ha sido una constante para las administraciones públicas: una necesidad que viene de lejos, bien conocida para los profesionales de los archivos y de la gestión documental.
Estamos experimentando, sin embargo, una aceleración considerable en las capacidades de captura, gestión y explotación de los datos generados por parte de cualquier organización, tanto a nivel tecnológico como organizacional. La definición de procesos y procedimientos orientados al dato, capaces de capturar información estructurada en sus partículas más concretas es una realidad creciente para las administraciones públicas, que ofrece interesantes potencialidades en la interacción con estos grandes volúmenes de información. Paradójicamente, esta potencialidad hace más presente que nunca la conocida metáfora del navegar o ahogarse en océanos de datos.
La interacción de los ciudadanos con nuestras administraciones públicas, o el mismo día a día de la tramitación administrativa orientada al dato -como la planteada en el diseño de Gestiona-, así como la gestión de los servicios y el patrimonio públicos son una fuente constante y primaria de datos en bruto, disponibles para su procesamiento y explotación.
Ahora bien, estas potencialidades conllevan necesidades específicas que permitan a las organizaciones la gestión de volúmenes de datos (y documentos) en situación de crecimiento exponencial, y que éstos se generen con la mayor calidad posible: los datos deberían capturarse bien estructurados, organizados y contextualizados.
Además, si ponemos el foco en el eje de la larga duración, nos encontramos con retos específicos derivados de la conservación y preservación a largo plazo de estos grandes volúmenes de información, de su contextualización y relación con procesos y procedimientos documentados, y de su representación en soportes documentales generados por las organizaciones.
Nos encontramos con retos específicos derivados de la conservación y preservación a largo plazo de estos grandes volúmenes de información
Depuración y pertinencia de los datos
Estos grandes volúmenes de datos, para su correcta explotación y preservación deben asegurar en su conjunto una serie de características bien conocidas por cualquier especialista en su tratamiento:
- Contexto: los datos en bruto, fuera de contexto y disociados de los procesos que los generaron pierden gran parte de su capacidad informativa.
- Corrección y uniformidad: los datos deben presentar formatos correctos y coherentes con la estructura en la que existen, así como representarse de forma normalizada en sus representaciones individuales.
- Integridad: los dataset a tratar deben mantener la integridad, evitando la existencia de lagunas, inconsistencias o fragmentación tanto en las representaciones individuales como estructurales.
Dependiendo de las fuentes consultadas, en cualquier trabajo de análisis y explotación de datos -y de nuevo, incluimos aquí los trabajos previos a la conservación y preservación a largo plazo de los mismos- se suele citar una horquilla de esfuerzo de entre el 65 y el 80% de tratamiento previo y tareas de depuración, contextualización y corrección de los datos a tratar.
Trabajos recientes (como el que nos presentaba recientemente Pilar Campos en el CNADE 2022) acometen directamente las técnicas necesarias para, desde el ámbito de los profesionales de la gestión documental y el archivo, llevar a cabo tareas de corrección y depuración.
Solo así, asegurando la pertinencia y disponibilidad de los datos, será posible llevar a cabo una correcta explotación y reutilización, que permita tanto tomar decisiones informadas y consecuentes como profundizar en la eficiencia de unas administraciones públicas cada vez más capaces de centrar sus recursos donde éstos tengan un mayor impacto en el servicio a la ciudadanía.
Así, las plataformas de Administración Electrónica deben ser capaces de ofrecer herramientas centradas en responder a estas necesidades. Capturar y generar datos son características inherentes a cualquier aplicativo, pero no basta con capturar datos en bruto: debemos disponer de armas y herramientas que faciliten y reduzcan las consabidas, pero necesarias, tareas de contextualización, corrección y depuración.
En este contexto, estaremos en disposición de reducir ese elevado porcentaje del esfuerzo del tratamiento previo de los datos obtenidos trasladándolo a tareas que realmente aporten valor en su análisis y explotación, y que incluso agilicen tanto los tiempos requeridos para su disposición y representación o reutilización en aplicativos integrados.
Disposición de reducir ese elevado porcentaje del esfuerzo del tratamiento previo de los datos obtenidos trasladándolo a tareas que realmente aporten valor en su análisis y explotación
Desde esta perspectiva, ¿qué herramientas tenemos a nuestro alcance para trabajar en la creación de datos de mayor calidad desde el diseño del propio sistema que los genera? ¿Y qué papel tenemos los especialistas en Gestión documental, archivo y Gestión de la información?
Normalización, organización y contexto: competencias del ámbito archivístico
Más allá de la propia experiencia en la definición de estructuras y esquemas de metadatos, el papel tradicional y conocimiento concreto de los profesionales del archivo y la gestión documental -si bien es cierto que el objeto de estos trabajos estaba plasmado en diferentes soportes no necesariamente electrónicos- tiene incidencia directa en la gestión, descripción, recuperación y tratamiento a largo plazo de elevados volúmenes de información
Las doctrinas archivísticas han profundizado en la creación de instrumentos y herramientas definidas, precisamente, con estos objetivos. Sabemos que este conocimiento nacido en el papel se venía trasladando desde hace años a entornos en soporte puramente electrónico. Y sabemos también que es perfectamente trasladable al ámbito de la gestión de los datos, estructuración de los datos, generación y tratamiento de dataset, etc.
Además, es natural a nuestro ámbito profesional el conocimiento profundo de los objetos que van a generar y recoger la mayoría de los datos producidos en cualquier plataforma de administración electrónica, productos de la tramitación administrativa. Las profesionales del archivo conocen bien la relación e interacción entre las partes mínimas que componen los activos de información – los datos- y los documentos que van a disponer, representar y en último término mantener sus valores informativos intactos.
Este conocimiento y técnicas tienen una aplicabilidad directa en el diseño de Gestiona en lo relativo a la relación de los modelos de datos, los procesos y procedimientos que los contextualizan, y los expedientes y documentos en que se representan.
La clasificación y descripción normalizada son técnicas que se adecúan tanto al tratamiento de documentos como de datos y estructuras de datos, que se unen a la experiencia en la generación de ontologías, diccionarios de datos y otros recursos referenciales.
|
Los profesionales del archivo cuentan además con el convencimiento y con las pautas de trabajo adecuadas, que tanto tienen que aportar en el ámbito de la gestión de datos. Criterios de normalización y de organización; ordenación y descripción como herramientas ante potenciales desbordes de captura y tratamiento de información; contextualización desde el diseño como garantía de conservación y pertinencia. |
Este planteamiento no implica -no podría ser de otra manera- erigir al archivo como responsable único respecto a la gestión y tratamiento de datos. Cuando hablamos de trabajar con datos, de su diseño y definición de las interacciones datos-sistemas-documentos, los profesionales de la gestión documental tienen valiosas capacidades, competencias y experiencias, pero no es un trabajo que deba abordarse de forma aislada. Será necesario trabajar codo con codo con profesionales de las Tecnologías de la Información, con científicos de datos y, en un contexto de administración pública electrónica, con especialistas jurídicos, donde cada perfil sea capaz de aportar facetas valiosas de conocimiento y experiencia. Solo así podrán abordarse los retos inherentes a este tipo de proyectos.
Soluciones metodológicas y soluciones tecnológicas
En cualquier caso, las herramientas técnicas y plataformas de administración electrónica deben estar a la altura de las exigencias y necesidades planteadas por la correcta gobernanza de los datos, y de los perfiles encargados de su captura y tratamiento.
Es necesario contar con herramientas que faciliten la generación ordenada y contextualizada de modelos de datos, y de sus productos datasets de la mayor calidad orientadas, como se planteaba más arriba, a reducir las cargas de trabajo derivadas de la depuración de datos. Herramientas que permitan, en definitiva, utilizar y llevar a la práctica desde el diseño ese conocimiento y buenas prácticas existentes en nuestro ámbito profesional, y aplicarlos directamente a los procesos y procedimientos definidos en la plataforma.
Para la generación de datos de la mayor calidad es crítico disponer de herramientas orientadas al diseño de estructuras de datos que permitan:
- Definir y establecer de forma sencilla normas y reglas de captura de datos específicas para cada tipología documental, e incluso para cada dato individual, incluyendo formatos, validaciones y límites (por ejemplo, campos Referencia Catastral o correspondientes a un número de cuenta bancaria, que disponen de sus propias lógicas de validación).
- Establecer pautas de normalización de base para determinadas tipologías de datos, incluyendo selección entre valores predeterminados o capturas automatizadas en función de la naturaleza del dato.
- Sistematizar la relación entre procesos, datos y documentos, permitiendo la relación de categorías y sistemas de clasificación y facilitando así la contextualización de los modelos de datos definidos en la plataforma.
- Responder a necesidades concretas derivadas de la coexistencia de diferentes lenguas oficiales, ofreciendo opciones de tratamiento unitario independientemente del idioma de captura utilizado.
La combinación de pautas, conocimientos y técnicas existentes en el ámbito de archivo con herramientas tecnológicas enfocadas en este ámbito tendrá como resultado natural la generación de estructuras de datos preparadas, desde su mismo diseño, para la producción de conjuntos de datos pertinentes, depurados, contextualizados y más próximos a su utilización, reutilización y explotación.


