La revolución tecnológica en la que estamos inmersos durante los últimos años, está generando una curva de crecimiento claramente exponencial entorno a la creación no contenida (e incontenible) de la unidad atómica de información relacionado con sus procesos, lo que todos ya citamos con matices casi totémicos como el dato.
No en vano, el volumen total de información generado por todos los sistemas que utilizamos en la actualidad ascendió, a lo largo del ejercicio 2019, a la no desdeñable cifra de 45 Zettabytes (ZB, para los que no estén familiarizados con esta unidad de medida, equivale a 1.000 millones de Terabytes). Y esta esfera global de datos (global datasphere), ha mantenido un crecimiento exponencial cuya aceleración apunta a que, en diversas predicciones, como la realizadas por IDC, se convierta en 175 Zettabytes para 2025, fruto de la llegada e implantación de tecnologías como el 5G y la consecuente revolución del internet de las cosas (IoT).
Muchos hablan por esto, del advenimiento de lo que han denominado la Nueva Era del Dato entre 2024 y 2025.
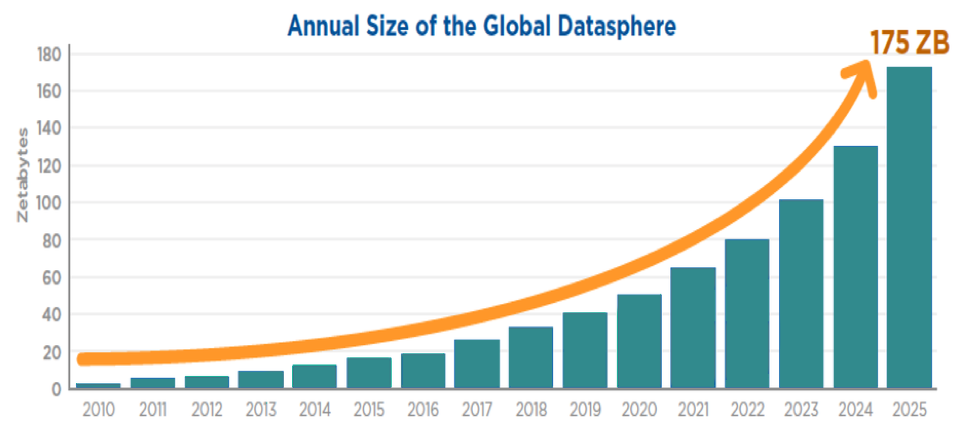
Y la realidad no ha hecho más que superar habitualmente dichas predicciones. Este tipo de volumetrías generará, y ya genera, serios problemas para su almacenamiento y salvaguarda, dado que las arquitecturas que lo soportan tienen que alinearse a dichas tasas de crecimiento (on premise, cloud, edge…). De hecho es habitual que los medios se hagan eco de problemas de almacenamiento de los principales distribuidores cloud, y de los nuevos techos generados tras su resolución.
Pero más allá de las cuestiones y estrategias de su almacenamiento, que son claramente un desafío tecnológico, lo realmente importante es que no olvidemos que el dato es un combustible que, sin un tratamiento, refinado y procesamiento adecuado, es sólo eso, un combustible con un altísimo potencial, una capacidad sin aprovechar. Y con las volumetrías comentadas, ese refinamiento, ese procesado en el que convirtamos el dato en información de valor para las organizaciones que los generamos, es un reto al que ya nos enfrentamos hoy en día.
Más allá de los titulares, ya nos encontramos inmersos en esa era de los datos, y la estrategia que adoptemos va a marcar cuánto nos aprovechemos de esa información.
En un enfoque “clásico”, las organizaciones contamos con diversos sistemas en los que introducimos información en repositorios de datos, a través de plataformas que facilitan dicho procesamiento. El usuario introduce y modifica información del sistema, apoyado en sistemas de filtrado, habitualmente toscos, y cuyo objetivo exclusivo, para lo que fueron creados, es propiamente la entrada de datos.
Como un primer paso en el camino de la obtención de información, se comienza dando servicio a través de informes, con cierta capacidad de selección previa a su generación, en las que el destinatario recibe información ya procesada y que la consume tal cual es servida.
Sin embargo, estas audiencias (conocidas en determinados contextos como “pasivas”, dado que no interactúan con el dato, únicamente lo consumen), cada vez necesitan que esta información tenga un comportamiento más dinámico. Puede que un informe periódico sea la solución en determinadas circunstancias, pero cada vez queremos recibirlos como resultado de que concurran una serie condiciones, y en distintos formatos, dispositivos, ocasiones… Así pues, cada vez más, deseamos que los contenidos que recibimos se adapten a nuestras necesidades e intereses. En nuestro contexto, un responsable de servicio requiere tener información procesada y detallada en el momento que exista una situación de alerta que precise de su actuación, por ejemplo, pero también un ciudadano espera obtener información asociada a sus trámites, obligaciones e incluso intereses en iniciativas como los portales al ciudadano. Estos usuarios conectan con la información gracias a sistemas adaptativos que ajustan los datos, la forma de mostrarlos, incluso el momento en que son generados, de acuerdo con las necesidades de cada contexto.
Y tenemos también consumidores de información con una capacidad más activa. Precisan seleccionar de forma interactiva, procesar, analizar la información introducida en los distintos sistemas origen, de modo que puedan obtener conclusiones, puntos de mejora o corrección, patrones de comportamiento…
Todo esto, además, de forma autónoma, y con herramientas que ayuden a que un conocimiento profundo de las arquitecturas que han soportado la creación de estos datos no sea necesario. Para ello es preciso contar con capas semánticas, que estos usuarios analíticos puedan utilizar para sus estudios, sin necesidad de conocimiento de BBDD o modelos complejos. Y toda esta información dentro de contextos gobernados, que garanticen la seguridad, así como la calidad de las conclusiones procesadas.
Aún más allá, el usuario genera su propio contenido analítico que puede compartir con el resto de la organización. Y el propio sistema debe ayudarle en dicha generación, haciendo propuestas de forma automática, de manera que, de acuerdo con el foco de estudio de dicho usuario, proponga aquellos análisis que habitualmente se ajustan más al mismo (a través de estrategias de machine learning) y contestando a las cuestiones de dicho usuario, ya no sólo con búsquedas tradicionales, sino también con búsquedas difusas e incluso procesamiento de lenguaje natural (Natural Language Processing), de manera que se le permita cuestionar sin ningún “patrón tecnológico” obteniendo análisis asociados a la cuestión procesada.
En este entorno, además, las “líneas rojas” tradicionales van a tener que desdibujarse.
La visión de sistemas de introducción y gestión de datos estancos que son “intervenidos” por otros analíticos procesados por audiencias distintas va a ser cosa del pasado. Sin que seamos incluso conscientes, nuestras plataformas tradicionales deberán incluir capacidades analíticas en sus procesos de introducción de información, con grandes capacidades de selección, elementos visuales intuitivos, nuevas dimensiones de análisis como la geográfica…
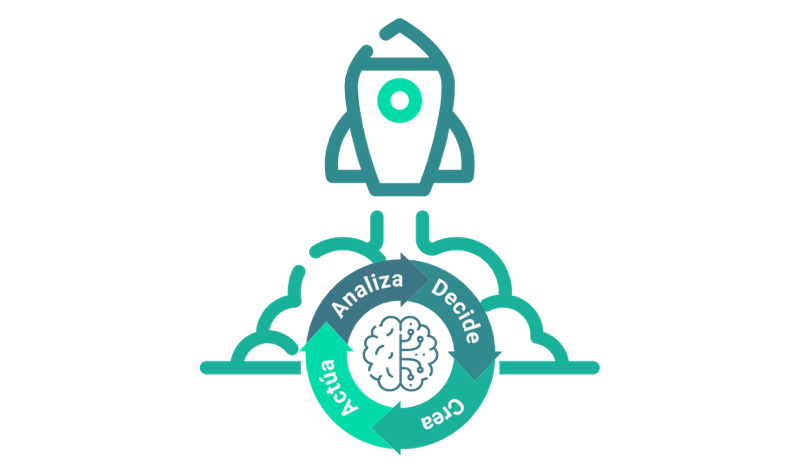
De esta forma, previo a la introducción de información, el usuario (apoyado en un sistema que aprende con él) analiza la situación a la que se enfrenta (obtiene información del ciudadano al que da servicio, un patrón de su comportamiento, un perfil de acuerdo con su situación censal…) selecciona la acción, procedimiento a aplicar, apoyado en dichas ayudas, volviendo a generar nueva información, nuevos datos. Y estos datos entran de nuevo en el ciclo de generación y análisis, nutriendo los siguientes procesos. Cada vez más con la necesidad, de forma integrada, prácticamente en tiempo real. Estas integraciones, y estos nuevos ciclos de trabajo, esta nueva inteligencia activa, van a pasar a formar parte de nuestro día a día, facilitando nuestra eficiencia, calidad de nuestro trabajo y la mejora de nuestros servicios prestados.
|
Por encima de cifras estratosféricas y predicciones superadas por la realidad, el ritmo en el que la información que procesamos crece nos obliga a que contemos con sistemas que se adapten de forma dinámica a las necesidades de nuestras organizaciones, de manera que podamos impulsarnos a través de los datos (ser más data-driven), que aprovechemos al máximo el combustible de esa ingente cantidad de datos que ya hoy estamos procesando. Es por esto que, lo que algunos profetizan como Nueva Era del Dato, ya no es una predicción, no es un “futurible”, y podemos afirmar que la Era del Dato es ahora. |

Con más de 20 años de investigación y colaboración en diferentes proyectos de analítica de datos. Cuenta con una amplia experiencia en diferentes tecnologías BI, con un foco especial en la plataforma analítica Qlik.

